ACL 2005 WORKSHOP ON
BUILDING AND USING PARALLEL TEXTS:
DATA-DRIVEN MACHINE TRANSLATION AND BEYOND
Shared Task: Exploiting Parallel Texts for Statistical Machine Translation
June 30, 2005, in conjunction with ACL 2005 in Ann Arbor, Michigan
The second shared task of the workshop is to build a probabilistic phrase translation table for phrase-based statistical machine translation (SMT). Evaluation is translation quality on an unseen test set.
We provide a parallel corpus as training data (with word alignment), a statistical machine translation decoder, and additional resources. Participants who use their own system are also very welcome.
Background
Phrase-based SMT is currently the best performing method in statistical machine translation. In short, the input is segmented into arbitrary multi-word units ("phrases", "segments", "blocks", "clumps"). Each of the units is translated into a target language unit. The units may be reordered. Here an example:
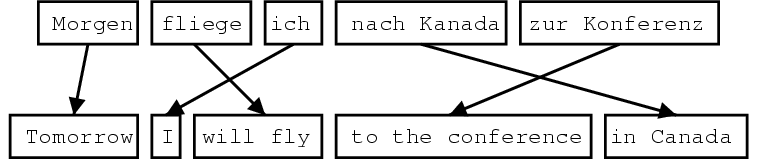
The core of a phrase-based statistical machine translation system is the phrase translation table: a lexicon of phrases that translate into each other, with a probability distribution, or any other arbitrary scoring method. The phrase translation table is trained from a parallel corpus.
You can find some more information on phrase-based SMT in the paper Statistical Phrase-Based Translation or the manual for the Pharaoh decoder.
Goals
The goals of staging this shared task are:
- get reference performance numbers
in a large-scale translation task for European languages
- pose special challenges with word order (German-English) and
morphology (Finnish-English)
- offer interested parties a (relatively) smooth start with
hands-on experience in state-of-the-art statistical machine translation
methods
- create publicly available data for machine translation
and machine translation evaluation
We hope that both beginners and established research groups
will participate in this task.
Task Description
We provide training data for four European language pairs, and a common framework (including a language model and a decoder). The task is to learn a phrase translation table. Given the provided framework, this table is used to translate a test set of unseen sentences in the source language. The translation quality is measured by the BLEU score, which measures overlap with a reference translation.
To have a common framework that allows for comparable results, and also to lower the barrier to entry, we provide
- a fixed training set
- a fixed language model
- a fixed decoder
Optionally, you may use
- a provided word alignment
Most current methods to train phrase translation tables build on a word alignment (i.e., the mapping of each word in the source sentence to words in the target sentence). Since word alignment is by itself a difficult task, we provide word alignments. These word alignments are acquired by automatic methods, hence they contain errors. You may get better performance by coming up with your own word alignment.
We also encourage your participation, if you use
- your own training corpus
- your own sentence alignment
- your own language model
- your own decoder
Your submission report should highlight in which ways your own methods
and data differ from the standard task.
We may break down submitted results in different tracks, based on what resources were used.
Provided Data
The provided data is taken from the Europarl corpus, which is freely available.
Please click on the links below to download the data.
Note that the training data is not lowercased. This may be useful for tagging and parsing tools. However, the phrase translation tables and language model use lowercased text. Since the provided development test set and final test set are mixed-cased, they have to be lowercased before translating.
Available Software (Linux)
Development Test Data
To test your phrase table during development, we provide a development test set of 2000 sentences.
Test Data
This is the official test data.
The official competition is over, but you may use the data for testing your own system.
Top Performances on Test Data
The test and training data will be kept available. You may want to compare your system
with the results in the official competition.
If you want to have your system score reported here, you must have it published
in a workshop, conference, or journal paper, so we can link to it.
Please send an email to pkoehn@inf.ed.ac.uk.
French-English
| System | BLEU | 1/2/3/4-gram precision |
| uw | 30.27 | 64.8/36.8/23.8/16.0 (BP=0.981) |
| upc-r | 30.20 | 63.9/36.2/23.3/15.6 (BP=0.998) |
| nrc | 29.53 | 63.7/35.8/22.7/14.9 (BP=0.997) |
| rali | 28.89 | 62.6/34.7/22.0/14.6 (BP=1.000) |
| cmu-bing | 27.65 | 63.1/34.0/20.9/13.3 (BP=0.995) |
| cmu-joy | 26.71 | 61.9/33.0/20.3/13.1 (BP=0.984) |
| saar | 26.29 | 60.8/32.5/20.1/12.9 (BP=0.982) |
| glasgow | 23.01 | 57.3/28.0/16.7/10.5 (BP=1.000) |
| uji | 21.25 | 59.8/27.7/14.8/8.3 (BP=1.000) |
| cots1 | 20.29 | 55.5/26.4/14.2/8.1 (BP=1.000) |
| cots2 | 17.82 | 53.0/23.6/12.1/6.6 (BP=1.000) |
Finnish-English
| System | BLEU | 1/2/3/4-gram precision |
| uw | 22.01 | 59.0/28.6/16.1/9.4 (BP=0.979) |
| nrc | 20.95 | 57.8/27.2/14.8/8.4 (BP=0.996) |
| upc-r | 20.31 | 56.6/26.0/14.3/8.3 (BP=0.993) |
| rali | 18.87 | 55.2/24.7/13.1/7.1 (BP=0.998) |
| saar | 16.76 | 58.4/26.3/14.2/8.0 (BP=0.819) |
| uji | 13.79 | 60.0/23.2/10.8/5.3 (BP=0.821) |
| cmu-joy | 12.66 | 53.9/21.7/10.7/5.7 (BP=0.775) |
Spanish-English
| System | BLEU | 1/2/3/4-gram precision |
| uw | 30.95 | 64.1/36.6/24.0/16.3 (BP=1.000) |
| upc-r | 30.07 | 63.1/35.8/23.2/15.6 (BP=1.000) |
| upc-m | 29.84 | 63.9/35.5/23.0/15.5 (BP=0.995) |
| nrc | 29.08 | 62.7/34.9/22.2/14.7 (BP=1.000) |
| rali | 28.49 | 62.4/34.5/21.9/14.4 (BP=0.992) |
| upc-j | 28.13 | 61.5/33.8/21.4/14.1 (BP=1.000) |
| saar | 26.69 | 61.0/33.1/20.7/13.5 (BP=0.973) |
| cmu-joy | 26.14 | 61.2/32.4/19.8/12.6 (BP=0.986) |
| uji | 21.65 | 59.7/27.8/15.2/8.7 (BP=1.000) |
| cots1 | 17.38 | 52.7/23.1/11.7/6.4 (BP=1.000) |
| cots2 | 17.28 | 52.2/23.0/11.7/6.4 (BP=1.000) |
German-English
| System | BLEU | 1/2/3/4-gram precision |
| uw | 24.77 | 62.2/31.8/18.8/11.7 (BP=0.965) |
| upc-r | 24.26 | 59.7/30.1/17.6/11.0 (BP=1.000) |
| nrc | 23.21 | 60.3/29.8/17.1/10.3 (BP=0.979) |
| rali | 22.91 | 58.9/29.0/16.8/10.3 (BP=0.982) |
| saar | 20.48 | 58.0/27.5/15.5/9.2 (BP=0.938) |
| cmu-joy | 18.93 | 59.2/26.8/14.3/8.1 (BP=0.914) |
| uji | 18.89 | 59.3/25.5/13.0/7.2 (BP=0.976) |
| cots1 | 14.92 | 51.6/20.7/9.7/4.8 (BP=1.000) |
| cots2 | 13.97 | 49.9/19.5/8.9/4.4 (BP=1.000) |
Participating Teams
- cmu-bing: Carnegie Mellon University - Bing Zhao
- cmu-joy: Carnegie Mellon University - Ying Zhang
- saar: Saarland University
- glasgow: University of Glasgow
- nrc: National Research Council
- rali: Univeristy of Montreal / RALI
- uji: University Jaume I
- upc-j: Polytechnic University of Catalonia - Jesus Gimenez
- upc-m: Polytechnic University of Catalonia - Marta Ruiz
- upc-r: Polytechnic University of Catalonia - Rafael Banchs
- uw: Univeristy of Washington
- cots: Commercial of the shelf systems, provided by Saarland University
How to Get Started
Here some quick steps to get started. We walk you through the process of downloading tools and data for French-English, and how to run the decoder with it. Click on the links to get the necessary software and data.
- Lowercase the development test set:
lowercase.perl < test2000.fr > test2000.fr.lowercase
- Run the decoder with the given phrase table and language model:
pharaoh -f pharaoh.fr.ini < test2000.fr.lowercase > test2000.fr.out
- The output file should start with
mr president , what we will have to respond to biarritz , is looking a little further .
the elect us as have just as much duty-bound to encourage it to make progress , albeit with adversity , that of passing on the messages we receive from the public opinion in all our countries .
with regard to the events of recent times , the issue of the price of fuel i also think that particularly well .
- Get the reference translations, lowercase them, and evaluate the output with BLEU:
lowercase.perl < test2000.en > test2000.en.lowercase
multi-bleu.perl test2000.en.lowercase < test2000.fr.out
- You should get a score of 26.76% BLEU.
Note that you may get a better score with a different parameter setting. See the Pharaoh manual for more details.
The phrase translation table is very big (1.3 GB), which may pose problems for running the decoder on a machine with little RAM. However, for a given test corpus, only a fraction of that table is needed. The script run-filtered-pharaoh.perl filters the phrase table for needed entries and runs the decoder on a filtered translation table (104 MB).
Its syntax is:
run-filtered-pharaoh.perl FILTER-DIR DECODE CONFIG TESTSET DECODER-PARAMETERS
For instance:
run-filtered-pharaoh.perl filtered.fr pharaoh pharaoh.fr.ini test2000.fr.lowercase "-monotone" > test2000.fr.out.monotone
You are now set to download the parallel corpora and build your own phrase translation table.