The baseline system will give performance numbers similar to the best systems that took part in the Shared Task of the ACL 2005 Workshop on building and using parallel texts. Software for download:
@InProceedings{koehn-monz:2006:WMT,
author = {Koehn, Philipp and Monz, Christof},
title = {Manual and Automatic Evaluation of Machine Translation between European Languages},
booktitle = {Proceedings on the Workshop on Statistical Machine Translation},
month = {June},
year = {2006},
address = {New York City},
publisher = {Association for Computational Linguistics},
pages = {102--121}
}
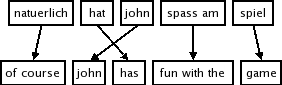
The core of a phrase-based statistical machine translation system is the phrase translation table: a lexicon of phrases that translate into each other, with a probability distribution, or any other arbitrary scoring method. The phrase translation table is trained from a parallel corpus.
You can find some more information on phrase-based SMT in the paper Statistical Phrase-Based Translation or the manual for the Pharaoh decoder.
-DBINARY_SEARCH_FOR_TTABLE) and mkcls, and unpack the training code. You may need to adjust path names in train-phrase-model.perl.
baseline.
Create a subdirectory The syntax of this command and additional options are explained in the training manual. Training may take up to a day.
For this parameter tuning you will need a development corpus of a few hundred sentences (more sentences may give more stable results, but is slower). You may use the development corpus that is provided along with the shared task for this, and store it in a new directory called You will also need a language model file, such as the ones provided with the shared task and store them in, for instance
Given the development set, you can proceed with parameter tuning:
This tortured syntax is explained in more detail in the training manual.
Running the minimum error rate training script may also take a day.
After that, you have a fully trained system.
The Pharaoh decoder can now be used to translate new text using the model. Typically, the generated phrase table is too large to fit into memory. So, directly running the decoder by
In this case, it is recommended to filter the phrase table first and then run the decoder. This can be done with:
Decoding time for these 2000 sentences is 1-2 hours.
System performance is evaluated with the script baseline/corpus and store there the training corpus, for instance:
zcat europarl.fr-en.fr.gz | lowercase.perl > baseline/corpus/europarl.fr-en.fr
zcat europarl.fr-en.en.gz | lowercase.perl > baseline/corpus/europarl.fr-en.en
Training a baseline system
You can now proceed to train a phrase model. This is done with the script train-phrase-model.perl:
train-phrase-model.perl --root-dir baseline --f fr --e en --corpus baseline/corpus/europarl.fr-en
Tuning parameter weights
An important second step of the training is the tuning of the model component weights. This is done with a script called minimum-error-rate-training.perl. You will also need the decoder Pharaoh and the finite state toolkit Carmel.
tuning.
zcat dev2006.fr.gz | head -500 | lowercase.perl > baseline/tuning/dev500.fr
zcat dev2006.en.gz | head -500 | lowercase.perl > baseline/tuning/dev500.en
baseline/lm/europarl.en.srilm.gz
minimum-error-rate-training.perl baseline/mert baseline/tuning/dev500.fr baseline/tuning/dev500.en 100 pharaoh.2004-05-10 "-f baseline/model/pharaoh.ini -dl 4 -b 0.03 -s 100 -lmodel-file baseline/lm/europarl.en.srilm.gz" "d:1,0.5-1.5 lm:1,0.5-1.5 tm:0.3,0.25-0.75;0.3,0.25-0.75;0.3,0.25-0.75;0.3,0.25-0.75;0,-0.5-0.5 w:0,-0.5-0.5" >& LOG.mert
Testing system performance
If you want to use to compare your system with the results from last year's workshop, you want to use the provided development test sets and store them in, for instance (this also needs to be lowercased)
baseline/evaluation/devtest2006.fr
baseline/evaluation/devtest2006.en
pharaoh.2004-05-10 -f baseline/mert/pharaoh.ini < in > out
may exceed the working memory of your machine.
run-filtered-pharaoh.perl baseline/evaluation/filtered pharaoh.2004-05-10 baseline/mert/pharaoh.ini baseline/evaluation/devtest2006.fr > baseline/evaluation/devtest2006.out
multi-bleu.perl, which is a simple implementation of the BLEU metric. You will need to provide the reference translation and the system output to the script.
multi-bleu.perl baseline/evaluation/devtest2006.en < baseline/evaluation/devtest2006.out
Additional help
Many questions regarding the Pharaoh system are answered by reading the training and decoder manuals. You can also contact Philipp Koehn.