Simulated Multiple Reference Training (SMRT)
Improves Low-Resource Machine Translation
Huda Khayrallah, Brian Thompson, Matt Post, Philipp Koehn
The Johns Hopkins University
Paper
This page releases data for the EMNLP 2020 paper, Simulated Multiple Reference Training Improves Low-Resource Machine Translation.
This work uses a pre-trained paragrapher model to augment the training data during training. It does so by sampling different paraphrases of the original reference translation, and training toward the paraphraser's distribution over the vocabulary at each time step.
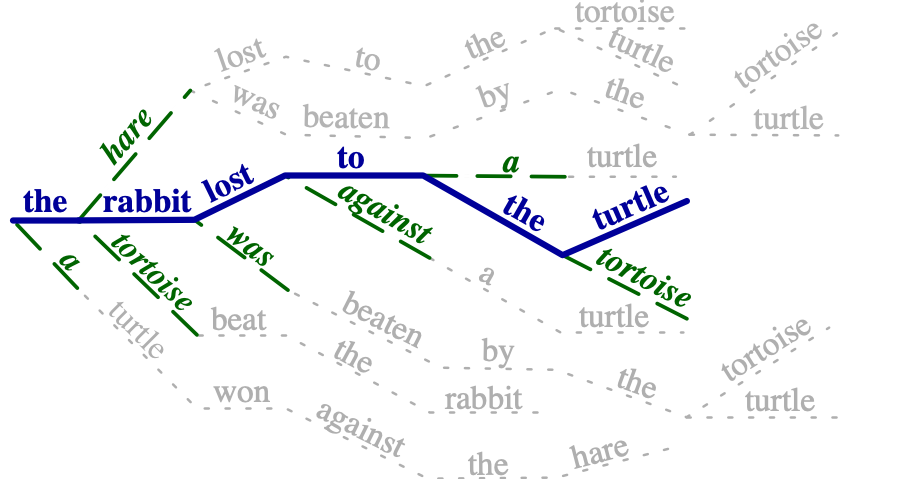 |
Each time a target sentence in the training data is used, a paraphrase is sampled from the many possible paraphrases. The training objective also takes into account the distribution over all the possible options along the sampled path. |
Abstract
Many valid translations exist for a given sentence, yet machine translation (MT) is trained with a single reference translation, exacerbating data sparsity in low-resource settings. We introduce Simulated Multiple Reference Training (SMRT), a novel MT training method that approximates the full space of possible translations by sampling a paraphrase of the reference sentence from a paraphraser and training the MT model to predict the paraphraser's distribution over possible tokens. We demonstrate the effectiveness of SMRT in low-resource settings when translating to English, with improvements of 1.2 to 7.0 BLEU. We also find SMRT is complementary to back-translation.
Code
The code and instructions to run SMRT are here.
Paraphraser model
The paraphraser used in the paper can be downloaded here.
If you use this paraphraser please also cite ParaBank2 (the data it was trained on) in addition to our work.
This contains the paraphraser model (paraphraser.pt), the vocabulary (dict.en.txt), and the SentencePiece model (sp.model.en). In order to use this paraphraser in MT training, you must apply this SentencePiece model to the target side of your training data, and use this dictionary in training.
Data Splits
The data splits needed to replicate our experiments on GlobalVoices can be downloaded here. We use v2017q3 as released on Opus and prepared by Casmacat. If you use this data split please cite Opus as the source of the data.
We train on 'train’, perform model selection from checkpoints & early stopping on 'valid’, and report on 'test’. There is also a devtest reserved called 'dev’ that we did not use in this work. 'test’ was the last 2000 lines of the file for each language pair, 'valid’ was the penultimate 2000 lines, and 'dev’ was the antepenultimate 2000 lines.
The data for each language pair from the main results table can be found in the directory $src-en. For Bengali-English (bn-en), there is a directory for each ablation size. The 'dev’/'valid’/'test’ files are consistent across all ablations. To ablate the data, we simply headed the file.
Each directory contains the raw data, as well as the data with the SentencePiece model applied. The English SentencePiece model is the one from the paraphraser (see above). The source paraphraser is trained only on the source language (or subset of the source, for Bengali). The SentencePiece model is included in each directory as sp.model.$src
The vocabulary of the target side must match that of the paraphraser. That means you must use the paraphraser's SentencePiece model on the target side of your data, and use its dictionary in training.
For the source, we train SentencePiece models on only the source language (or subset of the source, for Bengali) with a vocabulary size of 4,000.
Citations
Please cite this work as:
@inproceedings{khayrallah-etal-2020-simulated,
title={Simulated Multiple Reference Training Improves Low-Resource Machine Translation},
author={Huda Khayrallah and Brian Thompson and Matt Post and Philipp Koehn},
year={2020},
publisher = {Association for Computational Linguistics},
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing",
address = "Online",
month="nov"
}
If you use the GlobalVoices data, please cite Opus.
The data used to train the paraphraser comes from ParaBank2, please cite that work if you use this paraphraser.
If you replicate the models, please cite fairseq, FLoRes Parameters, and SentencePiece.