This shared task will examine automatic methods for estimating the quality of machine translation output at run-time, without relying on reference translations. In this third edition of the shared task, we will once again consider word-level and sentence-level estimation. However, this year we will focus on settings for quality prediction that are MT system-independent (e.g. Bicici, 2013) and rely on a limited number of training instances. More specifically, our tasks have the following goals:
Note that this year, for some of the subtasks, translations are produced in various ways: by RBMT, SMT, and hybrid MT systems, as well as by humans. In the datasets provided, no indication is given on how these various translations were generated.
Another important difference with respect to the previous years is that this year participants will only be able to use black-box features, since internal features features of the MT systems will not be provided.
Please note that any additional training data (from WMT12 or other sources) can be used for all tasks.
Results here, gold-standard labels for all languages here
This task is similar to the one in WMT12, with [1-3] scores for "perceived" post-editing effort used as quality labels, where:
For the training of prediction models, we provide a new dataset consisting of source sentences and their human translations, as well as two-three versions of machine translations (by an SMT system, an RBMT system and, for English-Spanish/German only, a hybrid system), all in the
As test data, for each language pair and MT system (or human translation) we provide a new set of translations produced by the same MT systems (and humans) as those used for the training data.
Additionally, for those interested, we provide some out of domain test data. These translations were annotated in the same way as above, each dataset by one LSP (one professional translator). However, they were generated using the LSP's own source data (a different domain from news), and own MT system (different from the three used for the official datasets). The results on these datasets will not be considered for the official ranking of the participating QE systems, but you are welcome to report on them in your paper. The true scores for these are also provided with the tars below:
Results here, gold-standard labels for all languages here
This task is similar to task 1.1 in WMT13, where we use use as quality score HTER, i.e.: the minimum edit distance between the machine translation and its manually post-edited version in [0,1]. Translations are given by one MT system only. Each of the training and test translations was post-edited by a professional translator, and HTER labels were computed using TERp (default settings: tokenised, case insensitive, etc., but capped to 1).
As training data, we provide a subset of the dataset from sub-task 1.1 above, but for English-Spanish only, and with a single translation per source sentence (the one by the MT systems):
As test data, we provide a new set of translations produced by the same SMT system used for the training data.
Results here, gold-standard labels for all languages here
This task is the same as Task 1.3 in WMT13: participating systems are required to produce for each sentence its expected post-editing time, a real valued estimate of the time (in milliseconds) it takes a translator to post-edit the translation. The training and test sets are similar to those from sub-task 1.2 (subject to filtering of outliers), above, will be provided, with the difference that the labels are now the number of milliseconds that were necessary to post-edit each translation. Each of the training and test translations was post-edited by a professional translator using a web-based tool to collect post-editing time on a sentence-basis.
Training data data:
Test data:
For each of the subtasks under Task 1, as in previous years, two variants of the results can be submitted:
For each language pair, evaluation will be performed against the true label and/or HTER ranking using the same metrics as in previous years:
For all these subtasks, the same 17 features used in WMT12-13 will be considered for the baseline systems. These systems will use SVM regression with an RBF kernel, as well as grid search algorithm for the optimisation of relevant parameters. QuEst will be used to build prediction models. For all subtasks we will use the same evaluation script.
Results here, gold-standard labels for all languages here
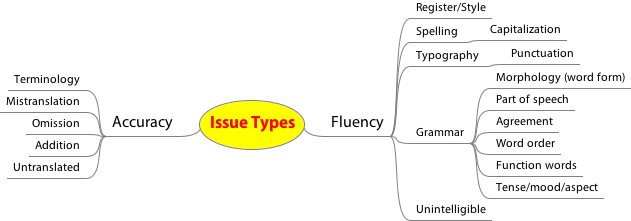
The data for this task is based on a subset of the same datasets provided in Task 1.1, for all language pairs, human and machine translations: those translations labelled 2 (near misses), plus additional data provided by industry (either on the news domain or on other domains, such as technical documentation, produced using their own MT systems, and also pre-labelled as 2s). All segments have been annotated with word-level labels by professional translations using the core categories in the MQM metric as error typology:
Participating systems will be required to produce for each token a label in one or more of the following settings:
As test data, we provide additional data points for all language pairs, human and machine translations:
Submissions for each language pair will evaluated in terms of classification performance (precision, recall, F-1) against the original labels in the three variants (binary, level 1 and multi-class). The main evaluation metric will be the average F1 for all but the "OK" class. For the non-binary variants, the average will be weighted by the frequency of the class in the test data. Evaluation script.
We suggest the following interesting resources that can be used as additional data for training (notice the difference in language pairs and/or text domains and/or MT systems):
These are the resources we have used to extract the baseline features in tasks 1.1, 1.2, 1.3:
English
Spanish
German
Giza tables
The output of your system a given subtask should produce scores for the translations at the segment-level formatted in the following way:
<METHOD NAME> <SEGMENT NUMBER> <SEGMENT SCORE> <SEGMENT RANK>Where:
METHOD NAME is the name of your
quality estimation method.SEGMENT NUMBER is the line number
of the plain text translation file you are scoring/ranking.SEGMENT SCORE is the predicted (HTER/time/likert) score for the
particular segment - assign all 0's to it if you are only submitting
ranking results. SEGMENT RANK is the ranking of
the particular segment - assign all 0's to it if you are only submitting
absolute scores. The output of your system should produce scores for the translations at the word-level formatted in the following way:
<METHOD NAME> <SEGMENT NUMBER> <WORD INDEX> <WORD> <DETAILED SCORE> <LEVEL 1 SCORE> <BINARY SCORE>Where:
METHOD NAME is the name of your quality estimation method.SEGMENT NUMBER is the line number of the plain text translation file you are scoring (starting at 0).WORD INDEX is the index of the word in the tokenized sentence, as given in the training/test sets (starting at 0).WORD actual word.MULTI SCORE is the detailed score within any of the dimensions: assign 'OK' for no issue, or one of the MQM categories as detailed in the Figure above for the following issue types (assign all 0's to it if you are not submitting multi-class scores):LEVEL 1 SCORE is either 'OK' for no issue, or 'Accuracy' or 'Fluency' - assign all 0's to it if you are not submitting level 1 scores.BINARY SCORE is either 'OK' for no issue or 'BAD' for any issue - assign all 0's to it if you are not submitting binary scores.
INSTITUTION-NAME_TASK-NAME_METHOD-NAME, where:
INSTITUTION-NAME is an acronym/short name for your institution, e.g. SHEF
TASK-NAME is one of the following: 1-1, 1-2, 1-3, 2.
METHOD-NAME is an identifier for your method in case you have multiple methods for the same task, e.g. 2_J48, 2_SVM
For instance, a submission from team SHEF for task 2 using method "SVM" could be named SHEF_2_SVM.
You are invited to submit a short paper (4 to 6 pages) to WMT describing your QE method(s). You are not required to submit a paper if you do not want to. In that case, we ask you to give an appropriate reference describing your method(s) that we can cite in the WMT overview paper.
| Release of training data | January 22, 2014 |
| Release of test data | March 7, 2014 |
| QE metrics results submission deadline | April 1, 2014 |
| Paper submission deadline | April 1, 2014 |
| Notification of acceptance | April 21, 2014 |
| Camera-ready deadline | April 28, 2014 |
For questions, comments, etc. email Lucia Specia lspecia@gmail.com.
Supported by the European
Commission under the
![]()
![]()
projects (grant numbers 296347 and 287576)