Phrase-based Tutorial
This tutorial describes the workings of the phrase-based decoder in Moses, using a simple model downloadable from the Moses website.
Content
A Simple Translation Model
Let us begin with a look at the toy phrase-based translation model that is
available for download at http://www.statmt.org/moses/download/sample-models.tgz. Unpack the tar ball and enter the directory sample-models/phrase-model.
The model consists of two files:
phrase-table the phrase translation table, and
moses.ini the configuration file for the decoder.
Let us look at the first line of the phrase translation table (file phrase-table):
der ||| the ||| 0.3 ||| |||
This entry means that the probality of translating the English word the from the German der is 0.3. Or in mathematical notation: p(the|der)=0.3. Note that these translation probabilities are in the inverse order due to the noisy channel model.
The translation tables are the main knowledge source for the machine translation decoder. The decoder consults these tables to figure out how to translate input in one language into output in another language.
Being a phrase translation model, the translation tables do not only contain single word entries, but multi-word entries. These are called phrases, but this concept means nothing more than an arbitrary sequence of words, with no sophisticated linguistic motivation.
Here is an example for a phrase translation entry in phrase-table:
das ist ||| this is ||| 0.8 ||| |||
Running the Decoder
Without further ado, let us run the decoder (it needs to be run from the sample-models directory) :
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini > out
Defined parameters (per moses.ini or switch):
config: phrase-model/moses.ini
input-factors: 0
lmodel-file: 8 0 3 lm/europarl.srilm.gz
mapping: T 0
n-best-list: nbest.txt 100
ttable-file: 0 0 0 1 phrase-model/phrase-table
ttable-limit: 10
weight-d: 1
weight-l: 1
weight-t: 1
weight-w: 0
Loading lexical distortion models...have 0 models
Start loading LanguageModel lm/europarl.srilm.gz : [0.000] seconds
Loading the LM will be faster if you build a binary file.
Reading lm/europarl.srilm.gz
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
****************************************************************************************************
The ARPA file is missing <unk>. Substituting log10 probability -100.000.
Finished loading LanguageModels : [2.000] seconds
Start loading PhraseTable phrase-model/phrase-table : [2.000] seconds
filePath: phrase-model/phrase-table
Finished loading phrase tables : [2.000] seconds
Start loading phrase table from phrase-model/phrase-table : [2.000] seconds
Reading phrase-model/phrase-table
----5---10---15---20---25---30---35---40---45---50---55---60---65---70---75---80---85---90---95--100
****************************************************************************************************
Finished loading phrase tables : [2.000] seconds
IO from STDOUT/STDIN
Created input-output object : [2.000] seconds
Translating line 0 in thread id 0
Translating: das ist ein kleines haus
Collecting options took 0.000 seconds
Search took 0.000 seconds
BEST TRANSLATION: this is a small house [11111] [total=-28.923] <<0.000, -5.000, 0.000, -27.091, -1.833>>
Translation took 0.000 seconds
Finished translating
% cat out
this is a small house
Here, the toy model managed to translate the German input sentence das ist ein kleines haus into the English this is a small house, which is a correct translation.
The decoder is controlled by the configuration file moses.ini. The file used in the example above is displayed below.
#########################
### MOSES CONFIG FILE ###
#########################
# input factors
[input-factors]
0
# mapping steps, either (T) translation or (G) generation
[mapping]
T 0
[feature]
KENLM name=LM factor=0 order=3 num-features=1 path=lm/europarl.srilm.gz
Distortion
WordPenalty
UnknownWordPenalty
PhraseDictionaryMemory input-factor=0 output-factor=0 path=phrase-model/phrase-table num-features=1 table-limit=10
[weight]
WordPenalty0= 0
LM= 1
Distortion0= 1
PhraseDictionaryMemory0= 1
[n-best-list]
nbest.txt
100
We will take a look at all the parameters that are specified here (and
then some) later. At this point, let us just note that the translation
model files and the language model file are specified here. In this
example, the file names are relative paths, but usually having full
paths is better, so that the decoder does not have to be run from a
specific directory.
We just ran the decoder on a single sentence provided on the command
line. Usually we want to translate more than one sentence. In this
case, the input sentences are stored in a file, one sentence per line.
This file is piped into the decoder and the output is piped into some
output file for further processing:
% moses -f phrase-model/moses.ini < phrase-model/in > out
Trace
How the decoder works is described in detail in the background section. But let us first develop an intuition by looking under the hood. There are two switches that force the decoder to reveal more about its inner workings: -report-segmentation and -verbose.
The trace option reveals which phrase translations were used in the
best translation found by the decoder. Running the decoder with the
segmentation trace switch (short -t) on the same example
echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -t >out
gives us the extended output
% cat out
this is |0-1| a |2-2| small |3-3| house |4-4|
Each generated English phrase is now annotated with additional
information:
this is was generated from the German words 0-1, das ist,
a was generated from the German word 2-2, ein,
small was generated from the German word 3-3, kleines, and
house was generated from the German word 4-4, haus.
Note that the German sentence does not have to be translated in
sequence. Here an example, where the English output is reordered:
echo 'ein haus ist das' | moses -f phrase-model/moses.ini -t -weight-overwrite "Distortion0= 0"
The output of this command is:
this |3-3| is |2-2| a |0-0| house |1-1|
Verbose
Now for the next switch, -verbose (short -v), that displays additional run time information. The verbosity of the decoder output exists in three levels. The default is 1. Moving on to -v 2 gives additional statistics for each translated sentences:
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -v 2
[...]
TRANSLATING(1): das ist ein kleines haus
Total translation options: 12
Total translation options pruned: 0
A short summary on how many translations options were used for the translation of these sentences.
Stack sizes: 1, 10, 2, 0, 0, 0
Stack sizes: 1, 10, 27, 6, 0, 0
Stack sizes: 1, 10, 27, 47, 6, 0
Stack sizes: 1, 10, 27, 47, 24, 1
Stack sizes: 1, 10, 27, 47, 24, 3
Stack sizes: 1, 10, 27, 47, 24, 3
The stack sizes after each iteration of the stack decoder. An iteration is the processing of all hypotheses on one stack: After the first iteration (processing the initial empty hypothesis), 10 hypothesis that cover one German word are placed on stack 1, and 2 hypotheses that cover two foreign words are placed on stack 2. Note how this relates to the 12 translation options.
total hypotheses generated = 453
number recombined = 69
number pruned = 0
number discarded early = 272
During the beam search a large number of hypotheses are generated (453). Many are discarded early because they are deemed to be too bad (272), or pruned at some later stage (0), and some are recombined (69). The remainder survives on the stacks.
total source words = 5
words deleted = 0 ()
words inserted = 0 ()
Some additional information on word deletion and insertion, two advanced options that are not activated by default.
BEST TRANSLATION: this is a small house [11111] [total=-28.923] <<0.000, -5.000, 0.000, -27.091, -1.833
Sentence Decoding Time: : [4.000] seconds
And finally, the translated sentence, its coverage vector (all 5 bits for the 5 German input words are set), its overall log-probability score, and the breakdown of the score into language model, reordering model, word penalty and translation model components.
Also, the sentence decoding time is given.
The most verbose output -v 3 provides even more information. In fact, it is so much, that we could not possibly fit it in this tutorial. Run the following command and enjoy:
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -v 3
Let us look together at some highlights. The overall translation score is made up from several components. The decoder reports these components, in our case:
The score component vector looks like this:
0 distortion score
1 word penalty
2 unknown word penalty
3 3-gram LM score, factor-type=0, file=lm/europarl.srilm.gz
4 Translation score, file=phrase-table
Before decoding, the phrase
translation table is consulted for possible phrase translations.
For some phrases, we find entries, for others we find nothing.
Here an excerpt:
[das ; 0-0]
the , pC=-0.916, c=-5.789
this , pC=-2.303, c=-8.002
it , pC=-2.303, c=-8.076
[das ist ; 0-1]
it is , pC=-1.609, c=-10.207
this is , pC=-0.223, c=-10.291
[ist ; 1-1]
is , pC=0.000, c=-4.922
's , pC=0.000, c=-6.116
The pair of numbers next to a phrase is the coverage, pC denotes the log of the phrase translation probability, after c the future cost estimate for the phrase is given.
Future cost is an estimate of how hard it is to translate different parts of the sentence. After looking up phrase translation probabilities, future costs are computed for all contigous spans over the sentence:
future cost from 0 to 0 is -5.789
future cost from 0 to 1 is -10.207
future cost from 0 to 2 is -15.722
future cost from 0 to 3 is -25.443
future cost from 0 to 4 is -34.709
future cost from 1 to 1 is -4.922
future cost from 1 to 2 is -10.437
future cost from 1 to 3 is -20.158
future cost from 1 to 4 is -29.425
future cost from 2 to 2 is -5.515
future cost from 2 to 3 is -15.236
future cost from 2 to 4 is -24.502
future cost from 3 to 3 is -9.721
future cost from 3 to 4 is -18.987
future cost from 4 to 4 is -9.266
Some parts of the sentence are easier to translate than others. For instance the estimate for translating the first two words (0-1: das ist) is deemed to be cheaper (-10.207) than the last two (3-4: kleines haus, -18.987). Again, the negative numbers are log-probabilities.
After all this preperation, we start to create partial translations by translating a phrase at a time. The first hypothesis is generated by translating the first German word as the:
creating hypothesis 1 from 0 ( <s> )
base score 0.000
covering 0-0: das
translated as: the
score -2.951 + future cost -29.425 = -32.375
unweighted feature scores: <<0.000, -1.000, 0.000, -2.034, -0.916>>
added hyp to stack, best on stack, now size 1
Here, starting with the empty initial hypothesis 0, a new hypothesis (id=1) is created. Starting from zero cost (base score), translating the phrase das into the carries translation cost (-0.916), distortion or reordering cost (0), language model cost (-2.034), and word penalty (-1). Recall that the score component information is printed out earlier, so we are able to interpret the vector.
Overall, a weighted log-probability cost of -2.951 is accumulated. Together with the future cost estimate for the remaining part of the sentence (-29.425), this hypothesis is assigned a score of -32.375.
And so it continues, for a total of 453 created hypothesis. At the end, the best scoring final hypothesis is found and the hypothesis graph traversed backwards to retrieve the best translation:
Best path: 417 <= 285 <= 163 <= 5 <= 0
Confused enough yet? Before we get caught too much in the intricate details of the inner workings of the decoder, let us return to actually using it. Much of what has just been said will become much clearer after reading the background information.
Tuning for Quality
The key to good translation performance is having a good phrase translation table. But some tuning can be done with the decoder. The most important is the tuning of the model parameters.
The probability cost that is assigned to a translation is a product of probability costs of four models:
- phrase translation table,
- language model,
- reordering model, and
- word penalty.
Each of these models contributes information over one aspect of the characteristics of a good translation:
- The phrase translation table ensures that the English phrases and the German phrases are good translations of each other.
- The language model ensures that the output is fluent English.
- The distortion model allows for reordering of the input sentence, but at a cost: The more reordering, the more expensive is the translation.
- The word penalty ensures that the translations do not get too long or too short.
Each of the components can be given a weight that sets its importance. Mathematically, the cost of translation is:
p(e|f) = phi(f|e)^weight_phi * LM(e)^weight_lm * D(e,f)^weight_d * W(e)^weight_w
The probability p(e|f) of the English translation e given the foreign input f is broken up into four models, phrase translation phi(f|e), language model LM(e), distortion model D(e,f), and word penalty W(e) = exp(length(e)). Each of the four models is weighted by a weight.
The weighting is provided to the decoder with the four parameters weight-t, weight-l, weight-d, and weight-w. The default setting for these weights is 1, 1, 1, and 0. These are also the values in the configuration file moses.ini.
Setting these weights to the right values can improve translation quality. We already sneaked in one example above. When translating the German sentence ein haus ist das, we set the distortion weight to 0 to get the right translation:
% echo 'ein haus ist das' | moses -f phrase-model/moses.ini -d 0
this is a house
With the default weights, the translation comes out wrong:
% echo 'ein haus ist das' | moses -f phrase-model/moses.ini
a house is the
What is the right weight setting depends on the corpus and the language pair. Ususally, a held out development set is used to optimize the parameter settings. The simplest method here is to try out with a large number of possible settings, and pick what works best. Good values for the weights for phrase translation table (weight-t, short tm), language model (weight-l, short lm), and
reordering model (weight-d, short d) are 0.1-1, good values for the word penalty (weight-w, short w) are -3-3. Negative values for the word penalty favor longer output, positive values favor shorter output.
Tuning for Speed
Let us now look at some additional parameters that help to speed
up the decoder. Unfortunately higher speed usually comes at cost of
translation quality. The speed-ups are achieved by limiting the search
space of the decoder. By cutting out part of the search space, we may
not be able to find the best translation anymore.
Translation Table Size
One strategy to limit the search space is by reducing the number of
translation options used for each input phrase, i.e. the number of
phrase translation table entries that are retrieved. While in the toy
example, the translation tables are very small, these can have
thousands of entries per phrase in a realistic scenario. If the
phrase translation table is learned from real data, it contains a lot
of noise. So, we are really interested only in the most probable ones
and would like to elimiate the others.
The are two ways to limit the translation table size: by a fixed
limit on how many translation options are retrieved for each input
phrase, and by a probability threshold, that specifies that the phrase
translation probability has to be above some value.
Compare the statistics and the translation output for our toy model, when no
translation table limit is used
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -ttable-limit 0 -v 2
[...]
Total translation options: 12
[...]
total hypotheses generated = 453
number recombined = 69
number pruned = 0
number discarded early = 272
[...]
BEST TRANSLATION: this is a small house [11111] [total=-28.923]
with the statistics and translation output, when a limit of 1 is used
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -ttable-limit 1 -v 2
[...]
Total translation options: 6
[...]
total hypotheses generated = 127
number recombined = 8
number pruned = 0
number discarded early = 61
[...]
BEST TRANSLATION: it is a small house [11111] [total=-30.327]
Reducing the number of translation options to only one per phrase, had a
number of effects: (1) Overall only 6 translation options instead of
12 translation options were collected. (2) The number of generated
hypothesis fell to 127 from 442, and no hypotheses were pruned out.
(3) The translation changed, and the output now has lower log-probability: -30.327 vs. -28.923.
Hypothesis Stack Size (Beam)
A different way to reduce the search is to reduce the size of
hypothesis stacks. For each number of foreign words translated,
the decoder keeps a stack of the best (partial) translations.
By reducing this stack size the search will be quicker, since less
hypotheses are kept at each stage, and therefore less hypotheses are
generated.
This is explained in more detail on the Background page.
From a user perspective, search speed is linear to the maximum stack
size. Compare the following system runs with stack size 1000, 100 (the
default), 10, and 1:
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -v 2 -s 1000
[...]
total hypotheses generated = 453
number recombined = 69
number pruned = 0
number discarded early = 272
[...]
BEST TRANSLATION: this is a small house [11111] [total=-28.923]
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -v 2 -s 100
[...]
total hypotheses generated = 453
number recombined = 69
number pruned = 0
number discarded early = 272
[...]
BEST TRANSLATION: this is a small house [11111] [total=-28.923]
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -v 2 -s 10
[...]
total hypotheses generated = 208
number recombined = 23
number pruned = 42
number discarded early = 103
[...]
BEST TRANSLATION: this is a small house [11111] [total=-28.923]
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -v 2 -s 1
[...]
total hypotheses generated = 29
number recombined = 0
number pruned = 4
number discarded early = 19
[...]
BEST TRANSLATION: this is a little house [11111] [total=-30.991]
Note that the number of hypothesis entered on stacks is getting smaller with the stack size: 453, 453, 208, and 29.
As we have previously described with translation table pruning, we may also want to use the relative scores of hypothesis for pruning instead of a fixed limit. The two strategies are also called histogram pruning and threshold pruning.
Here some experiments to show the effects of different stack size limits and beam size limits.
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -v 2 -s 100 -b 0
[...]
total hypotheses generated = 1073
number recombined = 720
number pruned = 73
number discarded early = 0
[...]
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -v 2 -s 1000 -b 0
[...]
total hypotheses generated = 1352
number recombined = 985
number pruned = 0
number discarded early = 0
[...]
% echo 'das ist ein kleines haus' | moses -f phrase-model/moses.ini -v 2 -s 1000 -b 0.1
[...]
total hypotheses generated = 45
number recombined = 3
number pruned = 0
number discarded early = 32
[...]
In the second example no pruning takes place, which means an exhaustive search is performed. With small stack sizes or small thresholds we risk search errors, meaning the generation of translations that score worse than the best translation according
to the model.
In this toy example, a worse translation is only generated with a stack size of 1. Again, by worse translation, we mean worse scoring according to our model (-30.991 vs. -28.923). If it is actually a worse translation in terms of translation quality, is another question. However, the task of the decoder is to find the best scoring translation. If worse scoring translations are of better quality, then this is a problem of the model, and should be resolved by better modeling.
Limit on Distortion (Reordering)
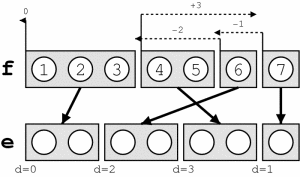
The basic reordering model implemented in the decoder is fairly weak. Reordering cost is measured by the number of words skipped when foreign phrases are picked out of order.
Total reordering cost is computed by D(e,f) = - Σi (d_i) where d for each phrase i is defined as d = abs( last word position of previously translated phrase + 1 - first word position of newly translated phrase ).
This is illustrated by the following graph:
This reordering model is suitable for local reorderings: they are
discouraged, but may occur with sufficient support from the language
model. But large-scale reorderings are often arbitrary and
effect translation performance negatively.
By limiting reordering, we can not only speed up the decoder,
often translation performance is increased. Reordering can be
limited to a maximum number of words skipped (maximum d)
with the switch -distortion-limit, or short -dl.
Setting this parameter to 0 means monotone translation (no reordering).
If you want to allow unlimited reordering, use the value -1.


 Language Models
Language Models