Factored Translation Models
The current state-of-the-art approach to statistical machine translation, so-called phrase-based models, are limited to the mapping of small text chunks (phrases) without any explicit use of linguistic information, may it be morphological, syntactic, or semantic. Such additional information has been demonstrated to be valuable by integrating it in pre-processing or post-processing.
However, a tighter integration of linguistic information into the translation model is desirable for two reasons:
- Translation models that operate on more general representations, such as lemmas instead of surface forms of words, can draw on richer statistics and overcome the data sparseness problems caused by limited training data.
- Many aspects of translation can be best explained on a morphological, syntactic, or semantic level. Having such information available to the translation model allows the direct modeling of these aspects. For instance: reordering at the sentence level is mostly driven by general syntactic principles, local agreement constraints show up in morphology, etc.
Therefore, we developed a framework for statistical translation models that tightly integrates additional information. Our framework is an extension of the phrase-based approach. It adds additional annotation at the word level. A word in our framework is not anymore only a token, but a vector of factors that represent different levels of annotation (see figure below).
Motivating Example: Morphology
One example to illustrate the short-comings of the traditional surface word approach in statistical machine translation is the poor handling of morphology. Each word form is treated as a token in itself. This means that the translation model treats, say, the word house completely independent of the word houses. Any instance of house in the training data does not add any knowledge to the translation of houses.
In the extreme case, while the translation of house may be known to the model, the word houses may be unknown and the system will not be able to translate it. While this problem does not show up as strongly in English - due to the very limited morphological production in English - it does constitute a significant problem for morphologically rich languages such as Arabic, German, Czech, etc.
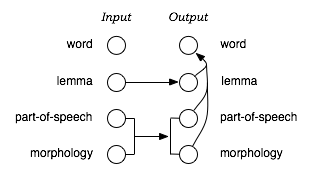
Thus, it may be preferably to model translation between morphologically rich languages on the level of lemmas, and thus pooling the evidence for different word forms that derive from a common lemma. In such a model, we would want to translate lemma and morphological information separately, and combine this information on the output side to ultimately generate the output surface words.
Such a model can be defined straight-forward as a factored translation model. See figure below for an illustration of this model in our framework.
Note that while we illustrate the use of factored translation models on such a linguistically motivated example, our framework also applies to models that incorporate statistically defined word classes, or any other annotation.
Decomposition of Factored Translation
The translation of factored representations of input words into the factored representations of output words is broken up into a sequence of mapping steps that either translate input factors into output factors, or generate additional output factors from existing output factors.
Recall the example of a factored model motivated by morphological analysis and generation. In this model the translation process is broken up into the following three mapping steps:
- Translate input lemmas into output lemmas
- Translate morphological and POS factors
- Generate surface forms given the lemma and linguistic factors
Factored translation models build on the phrase-based approach, which defines a segmentation of the input and output sentences into phrases. Our current implementation of factored translation models follows strictly the phrase-based approach, with the additional decomposition of phrase translation into a sequence of mapping steps. Since all mapping steps operate on the same phrase segmentation of the input and output sentence into phrase pairs, we call these synchronous factored models.
Let us now take a closer look at one example, the translation of the one-word phrase häuser into English. The representation of häuser in German is: surface-form häuser | lemma haus | part-of-speech NN | count plural | case nominative | gender neutral.
The three mapping steps in our morphological analysis and generation model may provide the following applicable mappings:
- Translation: Mapping lemmas
- haus -> house, home, building, shell
- Translation: Mapping morphology
- NN|plural-nominative-neutral -> NN|plural, NN|singular
- Generation: Generating surface forms
- house|NN|plural -> houses
- house|NN|singular -> house
- home|NN|plural -> homes
- ...
We call the application of these mapping steps to an input phrase expansion. Given the multiple choices for each step (reflecting the ambiguity in translation), each input phrase may be expanded into a list of translation options. The German häuser|haus|NN|plural-nominative-neutral may be expanded as follows:
- Translation: Mapping lemmas
- { ?|house|?|?, ?|home|?|?, ?|building|?|?, ?|shell|?|? }
- Translation: Mapping morphology
- { ?|house|NN|plural, ?|home|NN|plural, ?|building|NN|plural, ?|shell|NN|plural, ?|house|NN|singular,... }
- Generation: Generating surface forms
- { houses|house|NN|plural, homes|home|NN|plural, buildings|building|NN|plural, shells|shell|NN|plural, house|house|NN|singular, ... }
Statistical Model
Factored translation models follow closely the statistical modeling approach of phrase-based models (in fact, phrase-based models are a special case of factored models). The main difference lies in the preparation of the training data and the type of models learned from the data.
Training
The training data (a parallel corpus) has to be annotated with the additional factors. For instance, if we want to add part-of-speech information on the input and output side, we need to obtain part-of-speech tagged training data. Typically this involves running automatic tools on the corpus, since manually annotated corpora are rare and expensive to produce.
Next, we need to establish a word-alignment for all the sentences in the parallel training corpus. Here, we use the same methodology as in phrase-based models (symmetrized GIZA++ alignments). The word alignment methods may operate on the surface forms of words, or on any of the other factors. In fact, some preliminary experiments have shown that word alignment based on lemmas or stems yields improved alignment quality.
Each mapping step forms a component of the overall model. From a training point of view this means that we need to learn translation and generation tables from the word-aligned parallel corpus and define scoring methods that help us to choose between ambiguous mappings.
Phrase-based translation models are acquired from a word-aligned parallel corpus by extracting all phrase-pairs that are consistent with the word alignment. Given the set of extracted phrase pairs with counts, various scoring functions are estimated, such as conditional phrase translation probabilities based on relative frequency estimation or lexical translation probabilities based on the words in the phrases.
In our approach, the models for the translation steps are acquired in the same manner from a word-aligned parallel corpus. For the specified factors in the input and output, phrase mappings are extracted. The set of phrase mappings (now over factored representations) is scored based on relative counts and word-based translation probabilities.
The tables for generation steps are estimated on the output side only. The word alignment plays no role here. In fact, additional monolingual data may be used. The generation model is learned on a word-for-word basis. For instance, for a generation step that maps surface forms to part-of-speech, a table with entries such as (fish,NN) is constructed. One or more scoring functions may be defined over this table, in our experiments we used both conditional probability distributions, e.g., p(fish|NN) and p(NN|fish), obtained by maximum likelihood estimation.
An important component of statistical machine translation is the language model, typically an n-gram model over surface forms of words. In the framework of factored translation models, such sequence models may be defined over any factor, or any set of factors. For factors such as part-of-speech tags, building and using higher order n-gram models (7-gram, 9-gram) is straight-forward.
Combination of Components
As in phrase-based models, factored translation models can be seen as the combination of several components (language model, reordering model, translation steps, generation steps). These components define one or more feature functions that are combined in a log-linear model:
p(e|f) = exp Σi=1n λi hi(e,f)
To compute the probability of a translation e given an input sentence f, we have to evaluate each feature function hi. For instance, the feature function for a bigram language model component is (m is the number of words ei in the sentence e):
hlm(e,f) = plm(e) = p(e1) p(e2|e1) ... p(em|em-1)
Let us now consider the feature functions introduced by the translation and generation steps of factored translation models. The translation of the input sentence f into the output sentence e breaks down to a set of phrase translations {(fj,ej)}.
For a translation step component, each feature function ht is defined over the phrase pairs (fj,ej) given a scoring function τ:
ht(e,f) = Σj τ(fj,ej)''
For a generation step component, each feature function hg given a scoring function γ is defined over the output words ek only:
hg(e,f) = Σk γ(ek)
The feature functions follow from the scoring functions (τ, γ) acquired during the training of translation and generation tables. For instance, recall our earlier example: a scoring function for a generation model component that is a conditional probability distribution between input and output factors, e.g., γ(fish,NN,singular) = p(NN|fish).
The feature weights λi in the log-linear model are determined with the usual minimum error rate training method.
Efficient Decoding
Compared to phrase-based models, the decomposition of phrase translation into several mapping steps creates additional computational complexity. Instead of a simple table lookup to obtain the possible translations for an input phrase, now multiple tables have to be consulted and their content combined.
In phrase-based models it is easy to identify the entries in the phrase table that may be used for a specific input sentence. These are called translation options. We usually limit ourselves to the top 20 translation options for each input phrase.
The beam search decoding algorithm starts with an empty hypothesis. Then new hypotheses are generated by using all applicable translation options. These hypotheses are used to generate further hypotheses in the same manner, and so on, until hypotheses are created that cover the full input sentence. The highest scoring complete hypothesis indicates the best translation according to the model.
How do we adapt this algorithm for factored translation models? Since all mapping steps operate on the same segmentation, the expansions of these mapping steps can be efficiently pre-computed prior to the heuristic beam search, and stored as translation options. For a given input phrase, all possible translation options are thus computed before decoding (recall the earlier example, where we carried out the expansion for one input phrase). This means that the fundamental search algorithm does not change.
However, we need to be careful about combinatorial explosion of the number of translation options given a sequence of mapping steps. In other words, the expansion may create too many translation options to handle. If one or many mapping steps result in a vast increase of (intermediate) expansions, this may be become unmanageable. We currently address this problem by early pruning of expansions, and limiting the number of translation options per input phrase to a maximum number, by default 50. This is, however, not a perfect solution.


 Language Models
Language Models