OOVs
Contents
Handling Unknown Words
Unknown words are copied verbatim to the output. They are also scored by the language model, and may be placed out of order. Alternatively, you may want to drop unknown words. To do so add the switch -drop-unknown.
When translating between languages that use different writing sentences (say, Chinese-English), dropping unknown words results in better BLEU scores. However, it is misleading to a human reader, and it is unclear what the effect on human judgment is.
Options:
-drop-unknown -- drop unknown words instead of copying them into the output
Unsupervised Transliteration Model
Character-based translation model/Transliteration models have shown to be quite useful in MT for translating OOV words, for disambiguation and for translating closely related languages. A transliteration module as described in Durrani et al. (2014a) has been integrated into Moses. It is completely unsupervised and language independent. It extracts transliteration corpus from the parallel data and builds a transliteration model from it which can then be used to translate OOV word or named-entities.
Specification with experiment.perl
To enable transliteration module add the following to the EMS config file:
[TRAINING]
transliteration-module = "yes"
It will extract transliteration corpus from the word-aligned parallel data and learn a character-based model from it.
To use the post-decoding transliteration (Method 2 as described in the paper) add the following lines
post-decoding-transliteration = "yes"
To use the in-decoding method (Method 3 as described in the paper) add the following lines
in-decoding-transliteration = "yes"
transliteration-file = /file containing list of words to be transliterated/
Post-decoding method obtains the list of OOV words automatically by running the decoder. The in-decoding method requires the user to provide the list of words to be transliterated. This gives a freedom to transliterate any additional words that might be known to the translation model but can also be transliterated in some scenarios. For example "Little" can be translated to 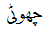 in Urdu when it is used as adjective and transliterated to
in Urdu when it is used as adjective and transliterated to 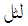 when it is a name as in "Stuart Little". You can add the OOV list as obtained from Method 2 if you don't want to add any other words. Transliterating all the words in the test-set might be helpful when translating between closely related language pairs such as Hindi-Urdu, Thai-Lao etc. See Durrani and Koehn (2014) for a case-study.
when it is a name as in "Stuart Little". You can add the OOV list as obtained from Method 2 if you don't want to add any other words. Transliterating all the words in the test-set might be helpful when translating between closely related language pairs such as Hindi-Urdu, Thai-Lao etc. See Durrani and Koehn (2014) for a case-study.
Steps for use outside experiment.perl
Execute command to train transliteration:
../mosesdecoder/scripts/Transliteration/train-transliteration-module.pl \
--corpus-f <foreign text> --corpus-e <target text> \
--alignment <path to aligned text> \
--moses-src-dir <moses decoder path> --external-bin-dir <external tools> \
--input-extension <input extension>--output-extension <output-extension> \
--srilm-dir <sri lm binary path> --out-dir <path to generate output files>
Train moses with transliteration option on
nohup nice train-model.perl -root-dir train -corpus <path to parallel corpus> \
-f <foreign> -e <target> -alignment grow-diag-final-and \
-reordering msd-bidirectional-fe -lm 0:3:<path to lm>:8 \
-external-bin-dir <external tools> -post-decoding-translit yes \
-transliteration-phrase-table <path to transliteration phrase table> >& training.out &
First pass decoding to generate output oov file and translation output without transliteration
nohup nice <path to moses> -f <moses.ini file> \
-output-unknowns <path to oov file to be output> \
< <path to test input> > <path to test output> 2> <path to trace output>
Second pass decoding to transliterate to the output
./post-decoding-transliteration.pl --moses-src-dir <moses decoder> \
--external-bin-dir <external tools> --transliteration-model-dir <transliteration model> \
--oov-file <oov file obtained in previous step> \
--input-file <translated file obtained in previous step> \
--output-file <output translated file> \
--input-extension <foreign> --output-extension <english> \
--language-model <path to language model> \
--decoder <moses executable>


 Language Models
Language Models