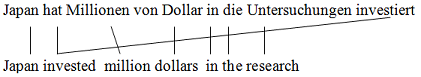Advanced Models
Content
Lexicalized Reordering Models
The default standard model that for phrase-based statistical machine translation is only conditioned on movement distance and nothing else. However, some phrases are reordered more frequently than others. A French adjective like extérieur typically gets switched with the preceding noun, when translated into English.
Hence, we want to consider a lexicalized reordering model that conditions reordering on the actual phrases. One concern, of course, is the problem of sparse data. A particular phrase pair may occur only a few times in the training data, making it hard to estimate reliable probability distributions from these statistics.
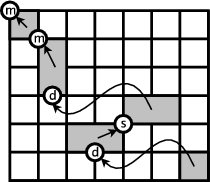
Therefore, in the lexicalized reordering model we present here, we only consider three reordering types: (m) monotone order, (s) switch with previous phrase, or (d) discontinuous. See below for an illustration of these three different types of orientation of a phrase.
To put it more formally, we want to introduce a reordering model po
that predicts an orientation type {m,s,d} given the phrase pair currently used in translation:
orientation ε {m, s, d}
po(orientation|f,e)
How can we learn such a probability distribution from the data? Again, we go back to the word alignment that was the basis for our phrase table. When we extract each phrase pair, we can also extract its orientation type in that specific occurrence.
Looking at the word alignment matrix, we note for each extracted phrase pair its corresponding orientation type. The orientation type can be detected, if we check for a word alignment point to the top left or to the top right of the extracted phrase pair. An alignment point to the top left signifies that the preceding English word is aligned to the preceding Foreign word. An alignment point to the top right indicates that the preceding English word is aligned to the following french word. See below for an illustration.
The orientation type is defined as follows:
- monotone: if a word alignment point to the top left exists, we have evidence for monotone orientation.
- swap: if a word alignment point to the top right exists, we have evidence for a swap with the previous phrase.
- discontinuous: if neither a word alignment point to top left nor to the top right exists, we have neither monotone order nor a swap, and hence evidence for discontinuous orientation.
We count how often each extracted phrase pair is found with each of the three orientation types. The probability distribution po is then estimated based on these counts using the maximum likelihood principle:
po(orientation|f,e) = count(orientation,e,f) / Σo count(o,e,f)
Given the sparse statistics of the orientation types, we may want to smooth the counts with the unconditioned maximum-likelihood probability distribution with some factor σ:
po(orientation) = Σf Σe count(orientation,e,f) / Σo Σf Σe count(o,e,f)
po(orientation|f,e) = (σ p(orientation) + count(orientation,e,f) ) / ( σ + Σo count(o,e,f) )
There are a number of variations of this lexicalized reordering model based on orientation types:
- bidirectional: Certain phrases may not only flag, if they themselves are moved out of order, but also if subsequent phrases are reordered. A lexicalized reordering model for this decision could be learned in addition, using the same method.
- f and e: Out of sparse data concerns, we may want to condition the probability distribution only on the foreign phrase (f) or the English phrase (e).
- monotonicity: To further reduce the complexity of the model, we might merge the orientation types swap and discontinuous, leaving a binary decision about the phrase order.
These variations have shown to be occasionally beneficial for certain training corpus sizes and language pairs. Moses allows the arbitrary combination of these decisions to define the reordering model type (e.g. bidirectional-monotonicity-f). See more on training these models in the training section of this manual.
Enhanced orientation detection
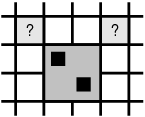
As explained above, statistics about the orientation of each phrase can be collected by looking at the word alignment matrix, in particular by checking the presence of a word
at the top left and right corners. This simple approach is capable of detecting a swap with a previous phrase that contains a word exactly aligned on the top right corner,
see case (a) in the figure below.
However, this approach cannot detect a swap with a phrase that does not contain a word with such an alignment, like the case (b). A variation to the way phrase orientation statistics are collected
is the so-called phrase-based orientation model by Tillmann (2004), which uses phrases both at training and decoding time. With the phrase-based orientation model, the case (b) is
properly detected and counted during training as a swap. A further improvement of this method is the hierarchical orientation model by Galley and Manning (2008), which is able to detect swaps or monotone arrangements between blocks even larger than the length limit imposed to phrases during training, and
larger than the phrases actually used during decoding. For instance, it can detect at decoding time the swap of blocks in the case (c) shown below.
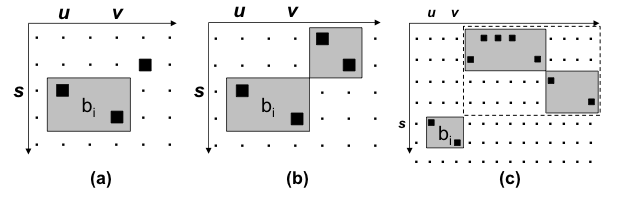
(Figure from Galley and Manning, 2008)
Empirically, the enhanced orientation methods should be used with language pairs involving significant word re-ordering.
Operation Sequence Model (OSM)
The Operation Sequence Model as described in Durrani et al. (2011) and Durrani et al. (2013) has been integrated into Moses.
What is OSM?
OSM is an N-gram-based translation and reordering model that represents aligned bilingual corpus as a sequence of operations and learns a Markov model over the resultant sequences. Possible operations are (i) generation of a sequence of source and target words (ii) insertion of gaps as explicit target positions for reordering operations, and (iii) forward and backward jump operations which do the actual reordering. The probability of a sequence of operations is defined according to an N-gram model, i.e., the probability of an operation depends on the n-1 preceding operations. Let O = o1, ... , oN be a sequence of operations as hypothesized by the translator to generate a word-aligned bilingual sentence pair < F;E;A >; the model is then defined as:
posm(F,E,A) = p(o1,...,oN) = ∏i p(oi|oi-n+1...oi-1)
The OSM model addresses several drawbacks of the phrase-based translation and lexicalized reordering models: i) it considers source and target contextual information across phrasal boundries and does not make independence assumption, ii) it is based on minimal translation units therefore does not have the problem of spurious phrasal segmentation, iii) it consider much richer conditioning than the lexcialized reordering model which only learns orientation of a phrase w.r.t previous phrase (or block of phrases) ignoring how previous words were translated and reordered. The OSM model conditions translation and reordering decisions on 'n' previous translation and reordering decisions which can span across phrasal boundaries.
A list of operations is given below:
Generate (X,Y): X and Y are source and target cepts in an MTU (minimal translation unit). This operation causes the words in Y and the first word in X to be added to the target and source strings respectively, that were generated so far. Subsequent words in X are added to a queue to be generated later.
Continue Source Cept: The source words added to the queue by the
Generate (X,Y) operation are generated by the
Continue Source Cept operation. Each Continue Source Cept operation removes one German word from the queue and copies it to the source string.
Generate Source Only (X): The words in X are added at the current position in the source string. This operation is used to generate an target word with no corresponding target word.
Generate Target Only (Y): The words in Y are added at the current position in the target string. This operation is used to generate an target word with no corresponding source word.
Generate Identical: The same word is added at the current position in both the source and target strings. The
Generate Identical operation is used during decoding for the translation of unknown words.
Insert Gap: This operation inserts a gap which acts as a placeholder for the skipped words. There can be more than one open gap at a time.
Jump Back (W): This operation lets the translator jump back to an open gap. It takes a parameter W specifying which gap to jump to. W=1 for the gap closest to the right most source word covered, W=2 for the second most closest and so on.
Jump Forward: This operation makes the translator jump to the right-most source word so far covered. It is performed when the next source word to be generated is at the right of the source word generated and does not follow immediately
The example shown in figure is deterministically converted to the following operation sequence:
Generate Identical -- Generate (hat investiert, invested) -- Insert Gap -- Continue Source Cept -- Jump Back (1) -- Generate (Millionen, million) -- Generate Source Only (von) -- Generate (Dollars, dollars) -- Generate (in, in) -- Generate (die, the) -- Generate (Untersuchungen, research)
Usage
To enable the OSM model in phrase-based decoder, just put the following in the EMS config file:
operation-sequence-model = "yes"
operation-sequence-model-order = 5
operation-sequence-model-settings = ""
Factored Model
Due to data sparsity the lexically driven OSM model may often fall back to very small context sizes. This problem is addressed in Durrani et al. (2014b) by learning operation sequences over generalized representations such as POS/Morph tags/word classes (See Section: Class-based Models). If the data has been augmented with additional factors, then use
operation-sequence-model-settings = "--factor 0-0+1-1"
"0-0" will learn OSM model over lexical forms and "1-1" will learn OSM model over second factor (POS/Morph/Cluster-id etc.). Note that using
operation-sequence-model-settings = ""
for a factor augmented training data is an error. Use
operation-sequence-model-settings = "--factor 0-0"
if you only intend to train OSM model over surface form in such a scenario.
In case you are not using EMS and want to train OSM model manually, you will need to do two things:
1) Run the following command
/path-to-moses/scripts/OSM/OSM-Train.perl --corpus-f corpus.fr --corpus-e corpus.en --alignment aligned.grow-diag-final-and --order 5 --out-dir /path-to-experiment/model/OSM --moses-src-dir /path-to-moses/ --srilm-dir /path-to-srilm/bin/i686-m64 --factor 0-0 --input-extension fr --output-extension en
2) Edit model/moses.ini to add
[feature]
...
OpSequenceModel name=OpSequenceModel0 num-features=5 path=/path-to-experiment/model/OSM/operationLM.bin
...
[weight]
...
OpSequenceModel0= 0.08 -0.02 0.02 -0.001 0.03
...
Interpolated OSM Model
OSM model trained from the plain concatenation of in-domain data with large and diverse multi-domain data is sub-optimal. When
other domains are sufficiently larger and/or different than the in-domain, the probability distribution can skew away from the target domain resulting in poor performance. The LM-like nature of the model provides motivation to apply methods such as perplexity optimization for model weighting. The idea is to train OSM model on each domain separately and interpolate them by minimizing optimizing perplexity on held-out tuning set. To know more read Durrani et al. (2015).
Usage
Provide tuning files as additional parameter in the settings. For example:
interpolated-operation-sequence-model = "yes"
operation-sequence-model-order = 5
operation-sequence-model-settings = "--factor 0-0 --tune /path-to-tune-folder/tune_file --srilm-dir /path-to-srilm/bin/i686-m64"
This method requires word-alignment for the source and reference tuning files to generate operation sequences. This can be done using force-decoding of tuning set or by aligning tuning sets along with the training. The folder should contain files as (for example (tune.de , tune.en , tune.align).
Interpolation script does not work with LMPLZ and will require SRILM installation.
Class-based Models
Automatically clustering the training data into word classes in order to obtain smoother distributions and better generalizations has been a widely known and applied technique in natural language processing. Using class-based models have shown to be useful when translating into morphologically rich languages. We use the mkcls utility in GIZA to cluster source and target vocabularies into classes. This is generally run during alignment process where data is divided into 50 classes to estimate IBM Model-4. Durrani et al. (2014b) found using different number of clusters to be useful for different language pairs. To map the data (say corpus.fr) into higher number of clusters (say 1000) use:
/path-to-GIZA/statmt/bin/mkcls –c1000 -n2 -p/path-to-corpus/corpus.fr -V/path-to-experiment/training/prepared.stepID/fr.vcb.classes opt
To annotate the data with cluster-ids add the following to the EMS-config file:
#################################################################
# FACTOR DEFINITION
[INPUT-FACTOR]
temp-dir = $working-dir/training/factor
[INPUT-FACTOR:mkcls]
### script that generates this factor
#
factor-script = "/path-to-moses/scripts/training/wrappers/make-factor-brown-cluster-mkcls.perl 0 $working-dir/training/prepared.stepID/$input-extension.vcb.classes"
[OUTPUT-FACTOR:mkcls]
### script that generates this factor
#
factor-script = "/path-to-moses/scripts/training/wrappers/make-factor-brown-cluster-mkcls.perl 0 $working-dir/training/prepared.stepID/$output-extension.vcb.classes"
#################################################################
Adding the above will augment the training data with cluster-ids. These can be enabled in different models. For example to train a joint-source target phrase-translation model, add the following to the EMS-config file:
[TRAINING]
input-factors = word mkcls
output-factors = word mkcls
alignment-factors = "word -> word"
translation-factors = "word+mkcls -> word+mkcls"
reordering-factors = "word -> word"
decoding-steps = "t0"
To train a target sequence model over cluster-ids, add the following to the EMS config-file
[LM]
[LM:corpus-mkcls]
raw-corpus = /path-to-raw-monolingual-data/rawData.en
factors = mkcls
settings = "-unk"
To train operation sequence model over cluster-ids, use the following in the EMS config-file
[TRAINING]
operation-sequence-model-settings = "--factor 1-1"
if you want to train both lexically driven and class-based OSM models then use:
[TRAINING]
operation-sequence-model-settings = "--factor 0-0+1-1"
Multiple Translation Tables and Back-off Models
Moses allows the use of multiple translation tables, but there are three different ways how they are used:
- both translation tables are used for scoring: This means that every translation option is collected from each table and scored by each table. This implies that each translation option has to be contained in each table: if it is missing in one of the tables, it can not be used.
- either translation table is used for scoring: Translation options are collected from one table, and additional options are collected from the other tables. If the same translation option (in terms of identical input phrase and output phrase) is found in multiple tables, separate translation options are created for each occurrence, but with different scores.
- the union of all translation options from all translation tables is considered. Each option is scored by each table. This uses a different mechanism than the above two methods and is discussed in the PhraseDictionaryGroup section below.
In any case, each translation table has its own set of weights.
First, you need to specify the translation tables in the section [feature] of the moses.ini configuration file, for instance:
[feature]
PhraseDictionaryMemory path=/my-dir/table1 ...
PhraseDictionaryMemory path=/my-dir/table2 ...
Secondly, you need to set weights for each phrase-table in the section [weight].
Thirdly, you need to specify how the tables are used in the section [mapping]. As mentioned above, there are two choices:
- scoring with both tables:
[mapping]
0 T 0
0 T 1
- scoring with either table:
[mapping]
0 T 0
1 T 1
Note: what we are really doing here is using Moses' capabilities to use different decoding paths. The number before "T" defines a decoding path, so in the second example are two different decoding paths specified. Decoding paths may also contain additional mapping steps, such as generation steps and translation steps using different factors.
Also note that there is no way to have the option "use both tables, if the phrase pair is in both table, otherwise use only the table where you can find it". Keep in mind, that scoring a phrase pair involves a cost and lowers the chances that the phrase pair is used. To effectively use this option, you may create a third table that consists of the intersection of the two phrase tables, and remove shared phrase pairs from each table.
PhraseDictionaryGroup: You may want to combine translation tables such that you can use any option in either table, but all options are scored by all tables. This gives the flexibility of the either option with the reliable scoring of the both option. This is accomplished with the PhraseDictionaryGroup interface that combines any number of translation tables on a single decoding path.
In the [feature] section, add all translation tables as normal, but specify the tuneable=false option. Then add the PhraseDictionaryGroup entry, specifying your translation tables as members and the total number of features (sum of member feature numbers). It is recommended to activate default-average-others=true. When an option is found in some member tables but not others, its feature scores default to 0 (log(1)), a usually unreasonably high score. Turning on the averaging option tells Moses to fill in the missing scores by averaging the scores from tables that have seen the phrase (similar to the "fill-up" approach, but allowing any table to be filled in by all other tables while maintaining a full feature set for each). See the notes below for other options.
In the [weight] section, specify all 0s for member tables except for the index of φ(e|f) (2 by default). This is only used for sorting options to apply the table-limit as the member tables will not contribute scores directly. The weights for the PhraseDictionaryGroup entry are the actual weights for the member tables in order. For instance, with 2 member tables of 4 features each, features 0-3 are the first table's 0-3 and 4-7 are the second table's 0-3.
Finally, only add a mapping for the index of the PhraseDictionaryGroup (number of member tables plus one).
[mapping]
0 T 2
[feature]
PhraseDictionaryMemory name=PhraseDictionaryMemory0 num-features=4 tuneable=false path=/my-dir/table1 ...
PhraseDictionaryMemory name=PhraseDictionaryMemory1 num-features=4 tuneable=false path=/my-dir/table2 ...
PhraseDictionaryGroup name=PhraseDictionaryGroup0 members=PhraseDictionaryMemory0,PhraseDictionaryMemory1 num-features=8 default-average-others=true
[weight]
PhraseDictionaryMemory0= 0 0 1 0
PhraseDictionaryMemory1= 0 0 1 0
PhraseDictionaryGroup0= 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2
Notes:
- You may want to add indicator features to tell Moses what translation table each option originates from. Activating
phrase-counts=true adds an indicator feature for each table to each option that returns 1 if the table contains the option and 0 otherwise. Similarly, activating word-counts=true adds a word count for each table. For instance, an option with target phrase length 3 would receive a 3 for each table that contains it and 0 for each that does not. Each of these options adds one feature per table, so set num-features and weights accordingly. (Adding both to the above example would yield num-features=12: 4 per model, 2 phrase counts, and 2 word counts)
Backoff Models: You may want to prefer to use the first table, and the second table only if there are
no translations to be found in the first table. In other words, the second table is only a back-off table
for unknown words and phrases in the first table. This can be specified by the option decoding-graph-back-off. The option also allows if the back-off table should only be used for single words (unigrams), unigrams and bigrams, everything up to trigrams, up to 4-grams, etc.
For example, if you have two translation tables, and you want to use the second one only for unknown words, you would specify:
[decoding-graph-backoff]
0
1
The 0 indicates that the first table is used for anything (which it always should be), and the 1 indicates that the second table is used for unknown n-grams up to size 1. Replacing it with a 2 would indicate its use for unknown unigrams and bigrams (unknown in the sense that the first table has no translations for it).
Also note, that this option works also with more complicated mappings than just a single translation
table. For instance the following specifies the use of a simple translation table first, and as a
back-off a more complex factored decomposition involving two translation tables and two generation tables:
[mapping]
0 T 0
1 T 1
1 G 0
1 T 2
1 G 1
[decoding-graph-backoff]
0
1
Caveat: Multiple Translation Tables and Lexicalized Reordering
You may specify any number of lexicalized reordering models. Each of them will score any translation option, no matter where it comes from. If a lexicalized reordering table does not have an entry for a translation option, it will not assign any score to it. In other words, such a translation option is given the probability 1 no matter how it is reordered. This may not be the way you want to handle it.
For instance, if you have an in-domain translation table and an out-of-domain translation table, you can also provide an in-domain reordering table and an out-of-domain reordering table. If a phrase pair occurs in both translation tables, it will be scored by both reordering tables. However, if a phrase pairs occurs only in one of the phrase tables (and hence reordering tables), it will be only score by one of them and get a free ride with the other. This will have the undesirable effect of discouraging phrase pairs that occur in both tables.
To avoid this, you can add default scores to the reordering table:
LexicalReordering name=LexicalReordering0 num-features=6 type=wbe-msd-bidirectional-fe-allff [...] default-scores=0.5,0.3,0.2,0.5,0.3,0.2
LexicalReordering name=LexicalReordering1 num-features=6 type=wbe-msd-bidirectional-fe-allff [...] default-scores=0.5,0.3,0.2,0.5,0.3,0.2
Global Lexicon Model
The global lexicon model predicts the bag of output words from the bag of input words. It does not use an explicit alignment between input and output words, so word choice is also influenced by the input context. For details, please check Mauser et al., (2009).
The model is trained with the script
scripts/training/train-global-lexicon-model.perl --corpus-stem FILESTEM --lex-dir DIR --f EXT --e EXT
which requires the tokenized parallel corpus, and the lexicon files required for GIZA++.
You will need the MegaM maximum entropy classifier from Hal Daume for training.
Warning: A separate maximum entropy classifier is trained for each target word, which is very time consuming. The training code is a very experimental state. It is very inefficient. For instance training a model on Europarl German-English with 86,700 distinct English words took about 10,000 CPU hours.
The model is stored in a text file.
File format:
county initiativen 0.34478
county land 0.92405
county schaffen 0.23749
county stehen 0.39572
county weiteren 0.04581
county europa -0.47688
Specification in moses.ini:
[feature]
GlobalLexicalModel input-factor=0 output-factor=0 path=.../global-lexicon.gz
[weight]
GlobalLexicalModel0= 0.1
Desegmentation Model
The in-Decoder desegmentation model is described in Salameh et al.(2016).
The desegmentation model extends the multi-stack phrase-based decoding paradigm to enable the extraction of word-level features inside morpheme-segmented models.
It assumes that the target side of the parallel corpus has been segmented into morphemes where a plus "+" at the end of a token is a prefix, and at the beginning is a suffix.
This allows us to define a complete word as a maximal morpheme sequence consisting of 0 or more prefixes, followed by at most one stem, and then 0 or more suffixes.
The word-level features extracted by this model are an unsegmented Language Model(word-level LM) score, contiguity feature, and WordPenalty that counts the number of words rather than the default one that counts morphemes.
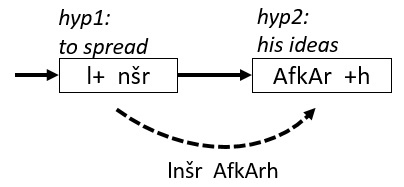
The word level features extracted from the hypotheses in the example are:
Unsegmented LM score for (lnšr AfkArh)
WordPenalty = 2
Contiguity feature: (2 0 0) indicating that desegmented tokens are aligned to continuous source tokens
Usage:
The feature is activated by adding the following line to the Moses config file
DesegModel name=LM1 path=/path/to/unsegmented/lm.blm deseg-path=/path/to/desegmentation/table optimistic=(default=y) deseg-scheme=(default=r)
- optimistic=(y or n) where n means it is delayed option(explained in the paper).
The optimistic option assumes that the morphemes form a complete word at the end of each hypothesis, while the delayed option desegments the morphemes when it guarantees that they form a complete word.
- The desegmentation table has the form of:
frequency(tab)UnsegmentedForm(tab)SegmentedForm.
You can download the desegmentaton table used for English Arabic translation here.
At this point, the frequency (count of occurrence of the unsegmented-segmented pair in a corpus) is not used but will later update it to handle multiple desegmentation options.
- deseg-scheme=(r or s) where r is rule-based desegmentation ONLY for Arabic and s is simple desgmentation that concatenates the tokens based on segmentation boundaries
Advanced Language Models
Moses supports various neural, bilingual and syntactic language models


 Language Models
Language Models